

Làm việc với Regular Expression trong C#
Đôi khi bạn cần kiểm tra dữ liệu nhập vào có đúng với cấu trúc và nội dung được quy định trước hay không. Ví dụ, bạn muốn bảo đảm người dùng nhập địa chỉ IP, số điện thoại, hay địa chỉ e-mail hợp lệ. Khi đó, bạn sẽ cần tới Regular Expression(RegEx), hay còn gọi là “Biểu thức chính quy“.
- RegEx là gì ?
- Xây dựng một RegEx
- Một số pattern mẫu
- #01. Username Regular Expression Pattern
- #02. Password Regular Expression Pattern
- #03. Hex color code Regular Expression Pattern
- #04. Email Regular Expression Pattern
- #05. Domain name Regular Expression Pattern
- #06. Image Regular Expression Pattern
- #07. IP Address Regular Expression Pattern
- #08. Format Time in 12 Hours Regular Expression Pattern
- #09. Format Time in 24 Hours Regular Expression Pattern
- #10. Format Date (dd/mm/yyyy) Regular Expression Pattern
- Các lớp để thao tác với RegEx trong .NET
- Lớp Regex
- Lớp Match
- Lớp MatchCollection
- Lớp Group
- Lớp GroupCollection
- Lớp Capture
- Lớp CaptureCollection
1. RegEx là gì ?
– Đó là một biểu thức ở dạng chuỗi mô tả một quy tắc dùng để so khớp mẫu văn bản. Bất kỳ chuỗi đầu vào nào thỏa quy tắc này sẽ được coi là một chuỗi hợp lệ.
– Việc sử dụng Regex sẽ giúp chúng ta loại bỏ được các dữ liệu không hợp lệ trong quá trình nhập liệu.
– Chúng ta có thể sử dụng Regex để tìm kiếm, so sánh, cắt ghép,… chuỗi dựa trên các mẫu văn bản (pattern).
2. Xây dựng một RegEx
– Trước tiên, bạn phải xác định cú pháp của biểu thức chính quy cho phù hợp với cấu trúc và nội dung của dữ liệu cần kiểm tra, đây là phần khó nhất khi sử dụng biểu thức chính quy.
– Biểu thức chính quy được xây dựng trên hai yếu tố : trực kiện (literal) và siêu ký tự (metacharacter).
- Trực kiện mô tả các ký tự có thể xuất hiện trong mẫu mà bạn muốn so trùng.
- Siêu ký tự hỗ trợ việc so trùng các ký tự đại diện (wildcard), tầm trị, nhóm, lặp, điều kiện, và các cơ chế điều khiển khác.
– Trong phạm vi bài viết này chúng ta không đi sâu vào cấu trúc của một RegEx mà sẽ tìm hiểu các trực kiện và siêu ký tự thường dùng để khi cần có thể xây dựng được những RegEx phù hợp với từng xử lý cụ thể.
Dưới đây là bảng liệt kê một số siêu ký tự thường dùng:
| Metacharacter | Description | Pattern | Matches |
| . | Đại diện cho mọi ký tự trừ ký tự xuống dòng (\n) Khi bạn muốn C# hiểu nó là một dấu chấm theo nghĩa thông thường bạn cần viết là “\\.” hoặc @”\.” |
a.e | “ave” in “nave” |
| \d | Ký tự chữ số, tương đương [0-9] | \d | “2”, “5” in “Today 2/5” |
| \D | Ký tự không phải chữ số, tương đương [^0-9] | \D | “T”, “o”, “d”, “a”, “y”, ” “, “/” in “Today 2/5” |
| \w | Ký tự word, gồm các chữ cái, chữ số và dấu gạch dưới _, tương đương [a-zA-Z0-9_] | \w | “I”, “D”, “2”, “_”, “5”, “c”, “o”, “m” in “ID@2_5.com” |
| \W | Không phải ký tự word, tương đương [^a-zA-Z0-9_] |
\W | “@”, “.” in “ID@2_5.com” |
| \s | Ký tự whitespace ( như khoảng trắng, tab, xuống dòng,… ) | \s\w\s | ” ” in “ID A1.3”“D ” in “ID A1.3” |
| \S | Ký tự không phải whitespace (\f, \n, \r, \t, \v) | \S\s\S\S\s | “I”, “D”, “A”, “1”, “.”, “3” in “ID A1.3”“D ” in “ID A1.3”” A” in “ID A1.3” |
| \b | Dùng để tìm ký tự liền nhau trong chữ (word). \b hoặc \B đứng ở đâu thì xem đó là giới hạn tìm kiếm trong chữ (Đánh dấu ranh giới giữa các từ, vị trí giữa một từ và một khoảng trắng). ・Ví dụ: “er\b” sẽ tương ứng với “er” trong “never” nhưng không tương ứng với “er” trong “verb”. ・Cứ một chuỗi các ký tự liền nhau nôm na gọi là một cụm (cách nhau bởi khoảng trắng,…). => chuỗi test có 3 cụm. A\b: lấy trên boundary => những ký tự A nằm cuối mỗi cụm. |
A\b | AHHA HAHAHAAA HAH |
| \B | ・Cách xác định chuỗi tìm kiếm ngược lại với \b. A\B: lấy trong cụm, trừ boundary => lấy những ký tự A từ đầu cho đến áp chót của mỗi cụm. |
A\B | AHHA HAHAHAAA HAH |
| ^ | Tìm chuỗi match tại ĐẦU của một chuỗi hoặc dòng. | ^\d{3} | “901” in “901-333-“ |
| $ | Tìm chuỗi match tại CUỐI chuỗi hoặc trước ký tự \n của chuỗi hoặc dòng. | \d{3}$-\d{3}$ | “333” in “-901-333”“-333” in “-901-333” |
| \A | Tìm chuỗi match tại ĐẦU của một chuỗi. | \A\d{3} | “901” in “901-333-“ |
| \Z | Tìm chuỗi match tại CUỐI chuỗi hoặc trước ký tự \n của chuỗi hoặc dòng. | -\d{3}\Z | “-333” in “-901-333” |
| \z | Tìm chuỗi match tại CUỐI của một chuỗi. | -\d{3}\z | “-333” in “-901-333” |
| | | Ngăn cách các biểu thức có thể so trùng (tương đương với phép or dùng khi muốn kết hợp nhiều điều kiện). Ví dụ AAA|ABA|ABB sẽ so trùng với AAA, ABA, hoặc ABB (các biểu thức được so trùng từ trái sang). |
th(e|is|at) | “this”, “the” in “this is the day at home” |
| * | Matches với các ký tự đứng trước * xuất hiện từ 0 lần trở lên. | \d*\.\d | “.0”, “19.9”, “219.9” |
| + | Matches với các ký tự đứng trước + xuất hiện từ 1 lần trở lên. | “be+” | “be” in “bent”“bee” in “been” |
| ? | Matches với các ký tự đứng trước ? xuất hiện 0 hoặc 1 lần. | “rai?n”A?B | “ran”, “rain”Sẽ khớp với B hoặc AB |
| { n } | Matches với các ký tự đứng trước chính xác n lần. | “,\d{3}” | “,043” in “1,043.6”“,876”, “,543”, “,210” in “9,876,543,210” |
| { n, } | Matches với các ký tự đứng trước ít nhất n lần. | “\d{2,}” | “166”, “29”, “1987” |
| { n , m } | Matches với các ký tự đứng trước ít nhất n lần, nhưng không vượt quá m lần. | “\d{3,5}” | “166”, “17668”“19302” in “193024” |
| [character_group] | Matches với bất kỳ ký tự đơn nào CÓ trong character_group. Mặc định, có phân biệt chữ hoa chữ thường. | [ae] | “a” in “gray”“a”, “e” in “lane” |
| [^character_group] | Matches với bất kỳ ký tự đơn nào KHÔNG CÓ trong character_group. Mặc định, có phân biệt chữ hoa chữ thường. | [^.com] | “i”, “n”, “h”, “h”, “n” in “minhhn.com” |
| [first – last] | Phạm vi ký tự: Matches với bất kỳ ký tự đơn nào trong khoảng từ first đến last. | [A-G] | “B”, “G”, “C” in “BLOG MINHHN.COM” |
| ( subexpression ) | Xác định một group (biểu thức con) xem như nó là một yếu tố đơn lẻ trong pattern. | (\w)\1 | “ee” in “deep” |
| \number | Backreference. Matches the value of a numbered subexpression. | (\w)\1 | “ee” in “seek” |
| (?:subexpression) | Defines a noncapturing group. | Write(?:Line)? | “WriteLine” in “Console.WriteLine()”“Write” in “Console.Write(value)” |
■ Ngoài ra, các bạn có thể xem thêm về Regular Expression ở link của CodeProject tại đây, hoặc của Microsoft tại đây.
■ Để test nhanh Regular Expression thì các bạn có thể vào trang http://regexr.com/ input biểu thức chính quy và dữ liệu muốn test sẽ biết ngay kết quả.
3. Một số pattern mẫu
Để hiểu rõ hơn về các siêu ký tự đã trình bày ở mục 2. Xây dựng một RegEx, chúng ta sẽ cùng phân tích một số pattern mẫu sau đây:
^[a-z0-9_-]{3,15}$
Description:
^ #Start of the line
[a-z0-9_-] # Match characters and symbols in the list, a-z, 0-9, underscore, hyphen
{3,15} # Length at least 3 characters and maximum length of 15
$ #End of the line
((?=.*\d)(?=.*[a-z])(?=.*[A-Z])(?=.*[@#$%]).{6,20})
Description:
( # start of group
(?=.*\d) # must contains one digit from 0-9
(?=.*[a-z]) # must contains one lowercase characters
(?=.*[A-Z]) # must contains one uppercase characters
(?=.*[@#$%]) # must contains one special symbols in the list "@#$%"
. # match anything with previous condition checking
{6,20} # length at least 6 characters and maximum of 20
) # end of group
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$
Description:
^ #start of the line
# # must constains a "#" symbols
( # start of group #1
[A-Fa-f0-9]{6} # any strings in the list, with length of 6
| # ..or
[A-Fa-f0-9]{3} # any strings in the list, with length of 3
) # end of group #1
$ #end of the line
"^[_A-Za-z0-9-\\+]+(\\.[_A-Za-z0-9-]+)*@" + "[A-Za-z0-9-]+(\\.[A-Za-z0-9]+)*(\\.[A-Za-z]{2,})$"
Description:
^ #start of the line
[_A-Za-z0-9-\\+]+ # must start with string in the bracket [ ], must contains one or more (+)
( # start of group #1
\\.[_A-Za-z0-9-]+ # follow by a dot "." and string in the bracket [ ], must contains one or more (+)
)* # end of group #1, this group is optional (*)
@ # must contains a "@" symbol
[A-Za-z0-9-]+ # follow by string in the bracket [ ], must contains one or more (+)
( # start of group #2 - first level TLD checking
\\.[A-Za-z0-9]+ # follow by a dot "." and string in the bracket [ ], must contains one or more (+)
)* # end of group #2, this group is optional (*)
( # start of group #3 - second level TLD checking
\\.[A-Za-z]{2,} # follow by a dot "." and string in the bracket [ ], with minimum length of 2
) # end of group #3
$ #end of the line
"^((?!-)[A-Za-z0-9-]{1,63}(?<!-)\\.)+[A-Za-z]{2,6}$"
Description:
^ #start of the line
( #Start of group #1
(?! -) #Can't start with a hyphen
[A-Za-z0-9-]{1,63} #Domain name is [A-Za-z0-9-], between 1 and 63 long
(?<!-) #Can't end with hyphen
\\. #Follow by a dot "."
)+ #End of group #1, this group must appear at least 1 time, but allowed multiple times for subdomain
[A-Za-z]{2,6} #TLD is [A-Za-z], between 2 and 6 long
$ #end of the line
@"([^\s]+(\.(?i)(jpg|png|gif|bmp))$)"
Description:
( #start of the group #1
[^\s]+ # must contains one or more anything (except white space)
( # start of the group #2
\. # follow by a dot "."
(?i) # ignore the case sensive checking for the following characters
( # start of the group #3
jpg # contains characters "jpg"
| # ..or
png # contains characters "png"
| # ..or
gif # contains characters "gif"
| # ..or
bmp # contains characters "bmp"
) # end of the group #3
) # end of the group #2
$ # end of the string
) #end of the group #1
@"^([01]?\d\d?|2[0-4]\d|25[0-5])\." + @"([01]?\d\d?|2[0-4]\d|25[0-5])\." + @"([01]?\d\d?|2[0-4]\d|25[0-5])\." + @"([01]?\d\d?|2[0-4]\d|25[0-5])$"
Description:
^ #start of the line
( # start of group #1
[01]?\\d\\d? # Can be one or two digits. If three digits appear, it must start either 0 or 1
# e.g ([0-9], [0-9][0-9],[0-1][0-9][0-9])
| # ...or
2[0-4]\\d # start with 2, follow by 0-4 and end with any digit (2[0-4][0-9])
| # ...or
25[0-5] # start with 2, follow by 5 and ends with 0-5 (25[0-5])
) # end of group #2
\. # follow by a dot "."
.... # repeat with 3 times (3x)
$ #end of the line
(1[012]|[1-9]):[0-5][0-9](\\s)?(?i)(am|pm)
Description:
( #start of group #1
1[012] # start with 10, 11, 12
| # or
[1-9] # start with 1,2,...9
) #end of group #1
: # follow by a semi colon ( : )
[0-5][0-9] # follw by 0..5 and 0..9, which means 00 to 59
(\\s)? # follow by a white space (optional)
(?i) # next checking is case insensitive
(am|pm) # follow by am or pm
([01]?[0-9]|2[0-3]):[0-5][0-9]
Description:
( #start of group #1 [01]?[0-9] # start with 0-9,1-9,00-09,10-19 | # or 2[0-3] # start with 20-23 ) #end of group #1 : # follow by a semi colon ( : ) [0-5][0-9] # follw by 0..5 and 0..9, which means 00 to 59
(0?[1-9]|[12][0-9]|3[01])/(0?[1-9]|1[012])/((19|20)\\d\\d)
Description:
( #start of group #1
0?[1-9] # 01-09 or 1-9
| # ..or
[12][0-9] # 10-19 or 20-29
| # ..or
3[01] # 30, 31
) #end of group #1
/ # follow by a "/"
( # start of group #2
0?[1-9] # 01-09 or 1-9
| # ..or
1[012] # 10,11,12
) # end of group #2
/ # follow by a "/"
( # start of group #3
(19|20)\\d\\d # 19[0-9][0-9] or 20[0-9][0-9]
) # end of group #3
4. Các lớp để thao tác với RegEx trong .NET
– Namespace System.Text.RegularExpressions có các lớp chính để thao tác như sau:
- Regex
- Match
- MatchCollection
- Group
- GroupCollection
- Capture
- CaptureCollection
– Nội dung chi tiết:
1. Lớp Regex
– Lớp Regex trong C# được sử dụng để biểu diễn một Regular Expression. Để sử dụng các phương thức của lớp này thì chúng ta tạo mới đối tượng Regex hoặc cũng có thể sử dụng trực tiếp bằng tên lớp Regex với một số phương thức tĩnh (static) mà không cần khởi tạo đối tượng.
– Trong ví dụ bên dưới, mình sẽ minh họa một số phương thức thường dùng của class Regex như: IsMatch, Split, Replace,…
using System.Text.RegularExpressions;
namespace MinhHoangBlog
{
class Program
{
static void Main(string[] args)
{
// Chuỗi dùng để kiểm tra
string str = "Welcome, to, blog, minhhn.com.";
// Tạo pattern để kiểm tra:
// chuỗi có chứa [khoảng trắng] hoặc [dấu phẩy và khoảng trắng] hay không
string pattern = " |, ";
// Tạo đối tượng Regex
Regex myRegex = new Regex(pattern);
//Hoặc: Regex myRegex = new Regex( " |, " );
// "IsMatch" cho biết: biểu thức chính quy "myRegex"
// có tìm thấy [khoảng trắng] hoặc [dấu phẩy và khoảng trắng]
// trong chuỗi đầu vào "str" đã chỉ định hay không.
if (myRegex.IsMatch(str))
{
// Trường hợp tìm thấy IsMatch = true,
// "Split" sẽ tách chuỗi theo pattern mà "myRegex" đã xác định.
string[] arrResult = myRegex.Split(str);
if (0 < arrResult.Length)
{
// In các chuỗi con đã tách được
foreach (string subStr in arrResult)
{
Console.WriteLine(subStr);
}
}
}
else
{
Console.WriteLine( "Chuoi khong match!!!" );
}
// Sử dụng 1 hàm overload khác của isMatch(chuoiKiemtra, pattern)
bool isMatch = Regex.IsMatch(str, pattern);
// true
Console.WriteLine();
string strCarot = "CarOt";
Console.WriteLine(Regex.IsMatch( strCarot, "carot" ));
// False
// Sử dụng 1 hàm overload khác của isMatch(chuoiKiemtra, pattern, optionKiemtra)
// Cung cấp thêm option không phân biệt chữ HOA thường.
Console.WriteLine(Regex.IsMatch(strCarot, "carot", RegexOptions.IgnoreCase));
// True
Console.WriteLine();
string inputSingleline = "<tag name=\"abc\">this\nis\na\ntext</tag>";
// <tag name = "abc"> this
// is
// a
// text </tag>
// Tạo đối tượng Regex, cung cấp thêm option Singleline.
Regex rx = new Regex("<tag name=\"(.*?)\">(.*?)</tag>", RegexOptions.Singleline);
// Regex.Replace(strOriginal, strReplacement)
// Nếu chuỗi gốc[strOriginal] thỏa mãn biểu thức chính quy đã tạo "rx"
// thì sẽ được thay thế bằng chuỗi[strReplacement]
string output = rx.Replace( inputSingleline, "[tag name=\"$1\"]$2[/tag]" );
Console.WriteLine(output);
Console.WriteLine();
// Regex.Replace(strOriginal, strPattern, strReplacement)
// Tìm trong chuỗi gốc[strOriginal], có phần nào thỏa mãn với [strPattern] hay không
// nếu có thì thay thế bằng chuỗi[strReplacement],
// nếu không thì không làm gì.
string result = Regex.Replace( "AX01_LO41_A", "AX\\d+_", "" );
Console.WriteLine("Chuoi sau khi replace: " + result);
Console.ReadKey();
}
}
}
[/code]
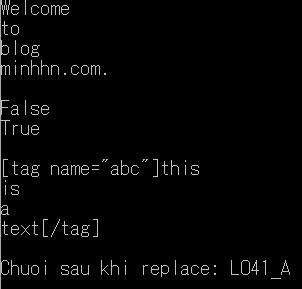
Demo Regex
2. Lớp Match và MatchCollection
– Khi áp dụng một biểu thức chính quy lên một chuỗi mẫu nào đó thì kết quả trả về có thể là một hoặc nhiều chuỗi con thoả mãn. Khi đó các chuỗi con sẽ được lưu vào trong 1 tập hợp có tên là MatchCollection, mỗi phần tử trong tập hợp có kiểu là Match.
– MatchCollection là 1 kiểu tập hợp chứa danh sách các đối tượng kiểu Match. Vì đây cũng là 1 tập hợp bình thường nên có thể thao tác duyệt phần tử, lấy số lượng phần tử,… như các tập hợp khác như List, HashSet,…
– Một số thuộc tính và phương thức thường dùng của 2 class Match và MatchCollection.
| Thuộc tính | Ý nghĩa |
| Class MatchCollection | |
| Count | Trả về số lượng các đối tượng Match có trong tập hợp. |
| Class Match | |
| Success | Trả về true/false cho biết có tìm được chuỗi con nào trùng khớp hay không. |
| Value | Trả về giá trị trùng khớp. |
| Length | Trả về độ dài của chuỗi con trùng khớp trong chuỗi gốc. |
| Index | Trả về vị trí đầu tiên của chuỗi con trùng khớp trong chuỗi gốc. |
| Empty | Trả về một đối tượng Match rỗng. Khi muốn kiểm tra 1 đối tượng Match có rỗng hay không ta sẽ so sánh chúng với Match.Empty chứ không phải với null nhé. |
| Captures | Trả về một CaptureCollection (danh sách các đối tượng Capture) được match bởi group. Kết quả có thể là 0 hoặc nhiều. |
| Groups | Trả về một GroupCollection (danh sách các đối tượng Group) được match bởi pattern regular expression. |
| Phương thức | Ý nghĩa |
| Class MatchCollection | |
| public void CopyTo(Array array, int arrayIndex); | Sao chép tất cả các phần tử của MatchCollection vào mảng array bắt đầu tại chỉ mục arrayIndex. |
| public IEnumerator GetEnumerator(); | Trả về một enumerator mà chứa tất cả các đối tượng Match trong MatchCollection. |
| Class Match | |
| public Match NextMatch(); | Trả về 1 đối tượng kiểu Match mới là giá trị trùng khớp tiếp theo (nếu có). |
– Example:
using System.Linq;
using System.Collections;
using System.Text.RegularExpressions;
namespace MinhHoangBlog
{
class Program
{
static void Main(string[] args)
{
string strText = "The founding date of minhhn.com blog: 2017/06/08";
Console.WriteLine(strText);
// Tạo đối tượng Regex, chỉ lấy số trong 1 chuỗi bất kỳ
Regex reg = new Regex( @"\d" );
/*
* ■ Trường hợp chỉ muốn lấy 1 giá trị match đầu tiên
*/
Match first = reg.Match(strText);
// Kiểm tra có chuỗi match hay không
if (Match.Empty != first)
{
Console.WriteLine("The first match: {0}", first.ToString());
}
/*
* ■ Trường hợp muốn lấy tất cả giá trị match: sử dụng MatchCollection
*/
// "reg.Matches" tìm tất cả các chuỗi con phù hợp với biểu thức chính quy "reg"
// mà có trong chuỗi "strText", rồi lưu tất cả các chuỗi match được
// vào tập hợp MatchCollection.
MatchCollection matchCol = reg.Matches(strText);
// Method CopyTo()
object[] arrObj = new object[matchCol.Count];
matchCol.CopyTo(arrObj, 0);
// Duyệt các phần tử trong MatchCollection bằng foreach
foreach (Match item in matchCol)
{
Console.WriteLine("Found: {0}", item.ToString() + " at position: " + item.Index);
}
// Method GetEnumerator()
IEnumerator enumerator = matchCol.GetEnumerator();
// Duyệt các phần tử trong MatchCollection bằng enumerator
while (enumerator.MoveNext())
{
object item = enumerator.Current;
Console.Write( item.ToString() + " " );
}
Console.WriteLine();
// Demo 1: Success, Value
string[] arrStr = new[] { "A", "AA", "AAA", "AAAA", "AAAAA" };
// Tạo Regex rx, với pattern check: chuỗi có từ 2 đến 4 ký tự A
Regex rx = new Regex( "^A{2,4}$" );
foreach (string str in arrStr)
{
// Tạo Match m để kiểm tra từng phần tử trong mảng[arrStr]
// có match với pattern check hay không.
Match m = rx.Match(str);
// Kiểm tra match
if (m.Success)
{
Console.WriteLine(m.Value);
// Hoặc: Console.WriteLine(str);
}
}
// Demo 2: Success, Value
string strA = "AA2 AA AAA3 AAA AAAA444 AAAAA5 AAAAA";
// Tạo pattern: kiểm tra chuỗi chứa 2 đến 4 ký tự A và 1 ký tự là số.
// Đối với pattern này thì:
// 1. Không có ký tự bắt đầu ^ và kết thúc chuỗi $ (vì chuỗi KHÔNG KẾT THÚC ĐÚNG CHÍNH XÁC từng phần tử như của mảng trên[arrStr])
// 2. Có 1 ký tự whitespace
string pattern = @"A{2,4}\d ";
// Tạo Match
Match m1 = Regex.Match(strA, pattern);
// Kiểm tra match
while (m1.Success)
{
Console.WriteLine(m1.Value);
// move to the next match
m1 = m1.NextMatch();
}
// Mở rộng: Convert MatchCollection to string array
string[] arrResult = Regex.Matches( strText, @"\b[A-Za-z\.]+\b" )
.Cast<Match>()
.Select(m => m.Value)
.ToArray();
Console.ReadKey();
}
}
}
[/code]
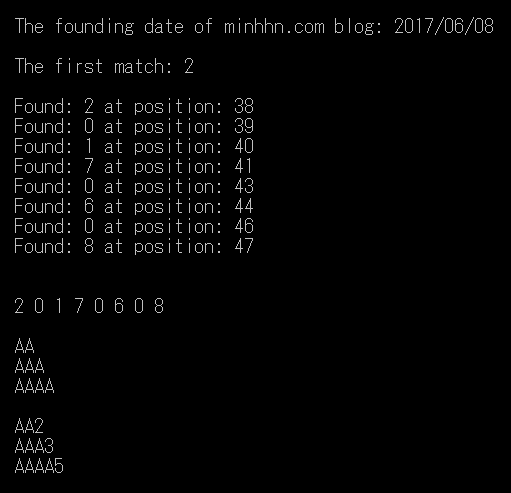
Demo Match và MatchCollection
– Lớp Group trong Regular Expression giúp chúng ta gom nhóm các biểu thức lại thành cụm và có thể đặt tên cho nhóm để dễ quản lý và thao tác.
– Lớp Group là 1 lớp đại diện cho 1 gom nhóm () trong biểu thức chính quy. Lớp Match là lớp thừa kế từ lớp Group.
– Cú pháp:
( ?<tên group> )
Trong đó:
- ( ) : là cú pháp gom nhóm các biểu thức chính quy đơn lẻ.
- ?<tên group> : là cú pháp đặt tên cho group. Cách đặt tên group cũng tuân theo quy luật đặt tên biến. Bạn có thể không đặt tên cho group cũng được.
– Để lấy ra danh sách các gom nhóm trong 1 chuỗi con kết quả, chúng ta dùng thuộc tính “Groups” của lớp Match (đã đề cập ở mục #2. Lớp Match và MatchCollection). Thuộc tính này trả về một GroupCollection. GroupCollection là 1 lớp chứa danh sách các gom nhóm trong biểu thức, mỗi phần tử của danh sách là một đối tượng kiểu Group.
– Ví dụ 1: Lấy ra group thời gian, địa chỉ IP, tên website từ chuỗi “08:06:17 127.0.0.0 minhhn.com“
using System.Text.RegularExpressions;
namespace MinhHoangBlog
{
class Program
{
static void Main(string[] args)
{
string str = "08:06:17 127.0.0.0 minhhn.com";
/*
* ■ Trường hợp CÓ ĐẶT TÊN cho Group,
* thì có thể lấy giá trị của group bằng 1 trong 2 cách:
* 1. Theo tên group đã đặt
* 2. Theo chỉ số của group
*
* ■ Trường hợp KHÔNG ĐẶT TÊN cho Group,
* thì chỉ lấy giá trị của group theo chỉ số của group.
*/
//group time = một hoặc nhiều digit hoặc dấu hai chấm, theo sau bởi khoảng trắng
string timePattern = @"(?<time>(\d|\: )+)\s"; // Giữa : và dấu ) không có khoảng trắng nha.
//group ip = một hoặc nhiều digit hoặc dấu chấm, theo sau bởi khoảng trắng
string ipPattren = @"(?<ip>(\d|\.)+)\s";
//group site = một hoặc nhiều ký tự không phải khoảng trắng
string sitePattern = @"(?<site>\S+)";
// Trường hợp không đặt tên cho group
/*
string timePattern1 = @"((\d|\: )+)\s"; // Giữa : và dấu ) không có khoảng trắng nha.
string ipPattren1 = @"((\d|\.)+)\s";
string sitePattern1 = @"(\S+)";
*/
// Tạo biểu thức chính quy
string pattern = timePattern + ipPattren + sitePattern;
Regex myRegex = new Regex(pattern);
// Lấy tập hợp những chuỗi trùng khớp với [pattern] trong chuỗi [str] MatchCollection matches = myRegex.Matches(str);
foreach (Match m in matches)
{
if (0 != m.Length)
{
Console.WriteLine("\nMatch: {0}", m.ToString());
// Lấy giá trị của group theo tên đã đặt
Console.WriteLine("\nTime: {0}", m.Groups["time"]);
Console.WriteLine("\nIP: {0}", m.Groups["ip"]);
Console.WriteLine("\nSite: {0}", m.Groups["site"]);
// Lấy giá trị của group theo chỉ số
Console.WriteLine("\nGroup 0: {0}", m.Groups[0]);
Console.WriteLine("\nGroup 1: {0}", m.Groups[1]);
Console.WriteLine("\nGroup 2: {0}", m.Groups[2]);
Console.WriteLine("\nGroup 3: {0}", m.Groups[3]);
Console.WriteLine("\nGroup 4: {0}", m.Groups[4]);
Console.WriteLine("\nGroup 5: {0}", m.Groups[5]);
}
}
Console.ReadKey();
}
}
}
[/code]
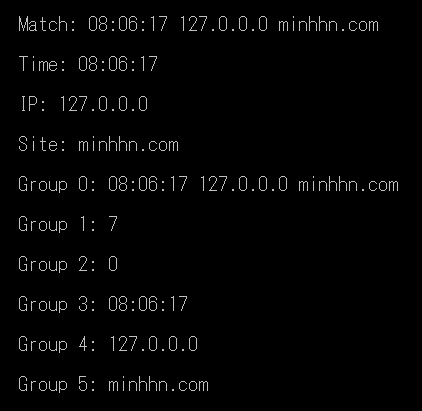
Demo Group và Groupcollection
– Ví dụ 2: Lấy ra group giờ, phút, giây từ chuỗi “08:06:17 127.0.0.0 minhhn.com“
using System.Text.RegularExpressions;
namespace MinhHoangBlog
{
class Program
{
static void Main(string[] args)
{
string str = "08:06:17 127.0.0.0 minhhn.com";
// Pattern lấy giờ, phút, giây là "\d+:\d+:\d+"
// Đặt tên 3 group là "hours", "minutes", "seconds"
string pattern = @"(?<hours>\d+): (?<minutes>\d+): (?<seconds>\d+)";
/* Giữa : và dấu ( không có khoảng trắng nha. */
// Tạo biểu thức chính quy
Regex myRegex = new Regex( pattern );
// Duyệt qua các kết quả trùng khớp
foreach (Match m in myRegex.Matches(str))
{
Console.WriteLine("\nMatch: " + m.ToString());
// Lấy giá trị của group theo tên đã đặt
Console.WriteLine("\nHours: " + m.Groups["hours"]);
Console.WriteLine("\nMinutes: " + m.Groups["minutes"]);
Console.WriteLine("\nSeconds: " + m.Groups["seconds"]);
// Lấy giá trị của group theo chỉ số
Console.WriteLine("\nGroup 0: {0}", m.Groups[0]);
Console.WriteLine("\nGroup 1: {0}", m.Groups[1]);
Console.WriteLine("\nGroup 2: {0}", m.Groups[2]);
Console.WriteLine("\nGroup 3: {0}", m.Groups[3]);
}
Console.ReadKey();
}
}
}
[/code]

Demo Group và Groupcollection
– Mỗi khi tìm thấy bất kỳ 1 chuỗi con nào (bao gồm cả các group) thì C# sẽ bắt nó lại và lưu vào 1 đối tượng có kiểu Capture. Và danh sách tất cả các Capture chính là 1 CaptureCollection.
– Lớp Group là lớp thừa kế từ lớp Capture.
– Ví dụ: Lấy ra thời gian, địa chỉ IP, tên website từ chuỗi “08:06:17 24H.Com.Vn 127.0.0.0 MinhHN.Com”
Chúng ta có đoạn code như sau:
// Giữa : và dấu ) không có khoảng trắng nha.
string pattern = @"(?<time>(\d|: )+)\s" + @"(?<site>\S+)\s" + @"(?<ip>(\d|\.)+)\s" + @"(?<site>\S+)";
Regex myRegex = new Regex(pattern);
foreach (Match item in myRegex.Matches(str))
{
Console.WriteLine("\nTime: " + item.Groups["time"]);
Console.WriteLine("\nSite: " + item.Groups["site"]);
Console.WriteLine("\nIp: " + item.Groups["ip"]);
Console.WriteLine("\nSite: " + item.Groups["site"]);
}
[/code]
・ Nhưng khi chạy chương trình kết quả thu được là:
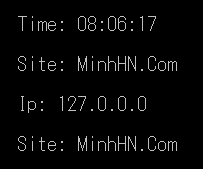
Kết quả chương trình
・ Chúng ta thấy có tới 2 tên webiste thoả mãn là 24H.Com.Vn và MinhHN.Com nhưng chương trình chỉ in ra được MinhHN.Com. Chúng ta có thể kiểm tra bằng phần mềm RegEx Tester để chắc rằng biểu thức mình viết đúng:
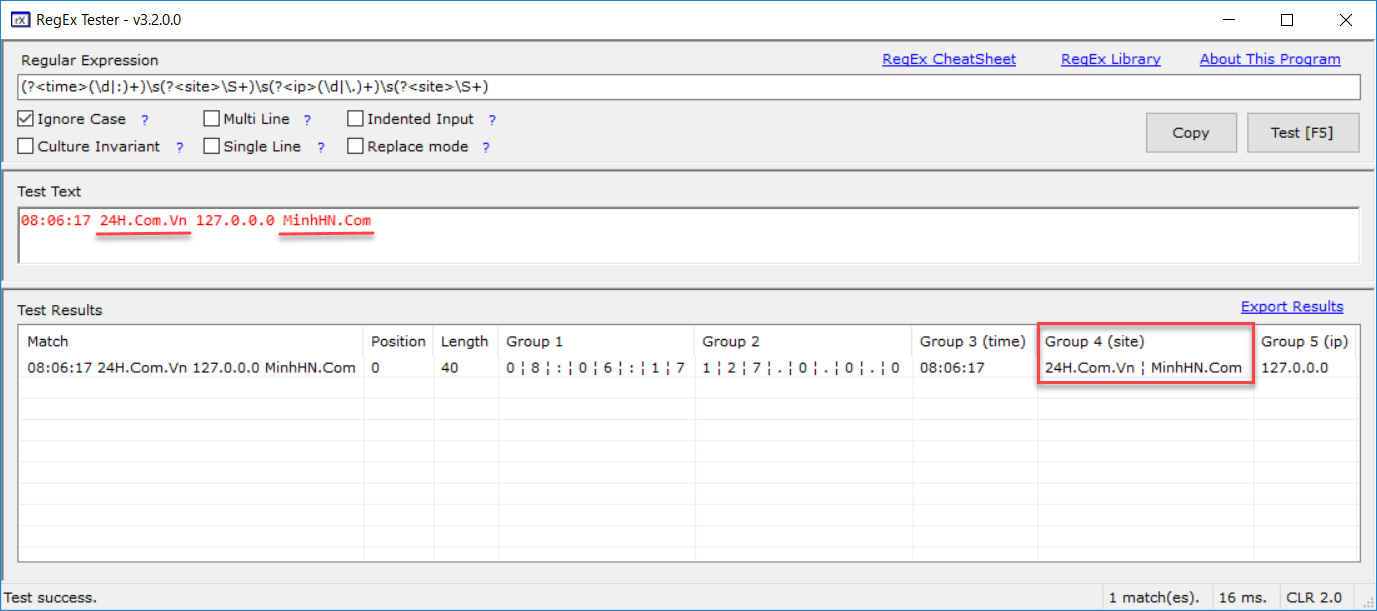
RegEx Tester
・ Các bạn có thể thấy ở Group 4 (site) trong hình. Rõ ràng ta lấy ra được 2 giá trị nhưng chỉ hiển thị được giá trị sau cùng.
・ Đến đây có thể bạn sẽ nói rằng chỉ cần đổi tên group khác đi là xong. Tuy nhiên, trong ví dụ trên mình chỉ có 2 site nhưng giả sử có đến 100 site trong chuỗi thì sao? Bạn cần đặt 100 biến khác nhau?
・ Vì thế chúng ta sẽ tận dụng đặc điểm của Capture và sử dụng chúng để giải quyết trong trường hợp này.
・ Chương trình sẽ như sau:
// Giữa : và dấu ) không có khoảng trắng nha.
string pattern = @"(?<time>(\d|: )+)\s" + @"(?<site>\S+)\s" + @"(?<ip>(\d|\.)+)\s" + @"(?<site>\S+)";
Regex myRegex = new Regex(pattern);
foreach (Match item in myRegex.Matches(str))
{
Console.WriteLine("\nTime: " + item.Groups["time"]);
Console.WriteLine("\nIp: " + item.Groups["ip"]);
Console.WriteLine("\nSite: " );
// Lấy ra danh sách CaptureCollection của group [site] CaptureCollection captures = item.Groups["site"].Captures;
// Duyệt qua danh sách CaptureCollection để lấy được Value của Capture
foreach (Capture capture in captures)
{
Console.WriteLine(capture.Value);
//Hoặc:
//Console.WriteLine(capture.ToString());
}
}
[/code]
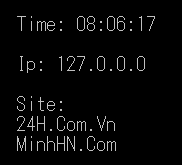
Demo Capture và CaptureCollection
■ Ngoài ra, các bạn có thể xem thêm về cách sử dụng của các lớp này trong namespace System.Text.RegularExpressions ở link mô tả của Microsoft tại đây.






Anh Minh ơi để trở thành kỹ sư BrSE cần những gì ạ?
Cơ bản là ngoại ngữ + kỹ thuật em nhé.